If you're a developer, you've used programming languages. They're awesome ways to make a computer do what you want it to. Maybe you've even dove deep and programmed in assembly or machine code. Many never want to come back. But some wonder, how can I torture myself more by doing more low level programming? I want to know more about how programming languages are made! All joking aside, writing a new language isn't as bad as it sounds, so if you have even a mild curiosity, I would suggest you stick around and see what it's about.
This post is meant to give a simple dive into how a programming language can be made, and how you can make your own special language. Maybe even name it after yourself. Who knows.
I also bet that this seems like an incredibly daunting task to take on. Do not worry, for I have considered this. I did my best to explain everything relatively simply without going on too many tangents. By the end of this post, you will be able to create your own programming language (there will be a few parts), but there's more. Knowing what goes on under the hood will make you better at debugging. You'll better understand new programming languages and why they make the decisions that they do. You can have a programming language named after yourself, if I didn't mention that before. Also, it's really fun. At least to me.
Compilers and Interpreters
Programming languages are generally high-level. That is to say, you're not looking at 0s and 1s, nor registers and assembly code. But, your computer only understands 0s and 1s, so it needs a way to move from what you read easily to what the machine can read easily. That translation can be done through compilation or interpretation.
Compilation is the process of turning an entire source file of the source language into a target language. For our purposes, we'll think about compiling down from your brand new, state of the art language, all the way down to runnable machine code.

My goal is to make the "magic" disappear
Interpretation is the process of executing code in a source file more or less directly. I'll let you think that's magic for this.
So, how do you go from easy-to-read source language to hard-to-understand target language?
Phases of a Compiler
A compiler can be split up into phases in various ways, but there's one way that's most common. It makes only a small amount of sense the first time you see it, but here it goes:
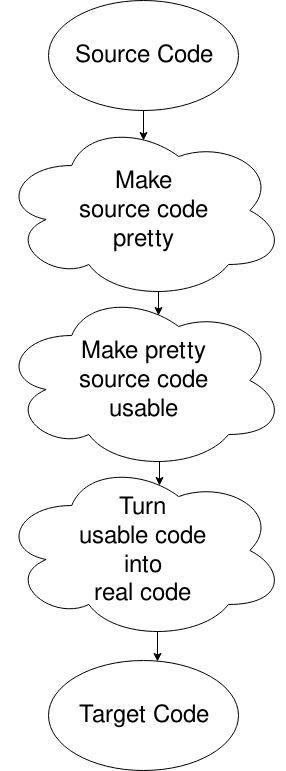
Oops, I picked the wrong diagram, but this will do. Basically, you get the source file, you put it into a format that the computer wants (removing white space and stuff like that), change it into something the computer can move around well in, and then generate the code from that. There's more to it. That's for another time, or for your own research if your curiosity is killing you.
Lexical Analysis
AKA "Making source code pretty"
Consider the following completely made up language that's basically just a calculator with semicolons:
// source.ect
3 + 3.2;
5.0 / 1.9;
6 * 2;
The computer doesn't need all of that. Spaces are just for our petty minds. And new lines? No one needs those. The computer turns this code that you see into a stream of tokens that it can use instead of the source file. Basically, it knows that 3 is an integer, 3.2 is a float, and + is something that operates on those two values. That's all the computer really needs to get by. It's the lexical analyzer's job to provide these tokens instead of a source program.
How it does that is really quite simple: give the lexer (a less pretentious sounding way of saying lexical analyzer) some stuff to expect, then tell it what to do when it sees that stuff. These are called rules. Here's an example:
int cout << "I see an integer!" << endl;
When an int comes through the lexer and this rule is executed, you will be greeted with a quite obvious "I see an integer!" exclamation. That's not how we'll be using the lexer, but it's useful to see that the code execution is arbitrary: there aren't rules that you have to make some object and return it, it's just regular old code. Can even use more than one line by surrounding it with braces.
By the way, we'll be using something called FLEX to do our lexing. It makes things pretty easy, but nothing is stopping you from just making a program that does this yourself.
To get an understanding of how we'll use flex, look at this example:
// scanner.lex
/* Definitions */
%{
#include <iostream>
using namespace std;
extern "C" int yylex();
%}
/* Rules next */
%%
[0-9]+.[0-9]+ cout << "FLOAT: (" << yytext << ")" << endl;
[0-9]+ cout << "INT: (" << yytext << ")" << endl;
"+" cout << "PLUS" << endl;
"-" cout << "MINUS" << endl;
"*" cout << "TIMES" << endl;
"/" cout << "DIVIDED BY" << endl;
";" cout << "SEMICOLON" << endl;
[\t\r\n\f] ; /* ignore whitespace */
%%
/* Code */
int main() {
yylex();
}
This introduces a few new concepts, so let's go over them:
%% is used to separate sections of the .lex file. The first section is declarations - basically variables to make the lexer more readable. It's also where you import, surrounded by %{ and %}.
Second part is the rules, which we saw before. These are basically a large if else if block. It will execute the line with the longest match. Thus, even if you change the order of the float and int, the floats will still match, as matching 3 characters of 3.2 is more than 1 character of 3. Note that if none of these rules are matched, it goes to the default rule, simply printing the character to standard out. You can then use yytext to refer to what it saw that matched that rule.
Third part is the code, which is simply C or C++ source code that is run on execution. yylex(); is a function call which runs the lexer. You can also make it read input from a file, but by default it reads from standard input.
Say you created these two files as source.ect and scanner.lex. We can create a C++ program using the flex command (given you have flex installed), then compile that down and input our source code to reach our awesome print statements. Let's put this into action!
evan:ectlang/ $ flex scanner.lex
evan:ectlang/ $ g++ lex.yy.c -lfl
evan:ectlang/ $ ./a.out < source.ect
INT: (3)
PLUS
FLOAT: (3.2)
SEMICOLON
FLOAT: (5.0)
DIVIDED BY
FLOAT: (1.9)
SEMICOLON
INT: (6)
TIMES
INT: (2)
SEMICOLON
evan:ectlang/ $
Hey, cool! You're just writing C++ code that matches input to rules in order to do something.
Now, how do compilers use this? Generally, instead of printing something, each rule will return something - a token! These tokens can be defined in the next part of the compiler...
Syntax Analyzer
AKA "Making pretty source code usable"
It's time to have fun! Once we get here, we start to define the structure of the program. The parser is just given a stream of tokens, and it has to match elements in this stream in order to make the source code have structure that's usable. To do this, it uses grammars, that thing you probably saw in a theory class or heard your weird friend geeking out about. They're incredibly powerful, and there's so much to go into, but I'll just give what you need to know for our sorta dumb parser.
Basically, grammars match non-terminal symbols to some combination of terminal and non-terminal symbols. Terminals are leaves of the tree; non-terminals have children. Don't worry about it if that doesn't make sense, the code will probably be more understandable.
We'll be using a parser generator called Bison. This time, I'll split the file up into sections for explanation purposes. First, the declarations:
// parser.y
%{
#include <iostream>
using namespace std;
extern "C" void yyerror(char *s);
extern "C" int yyparse();
%}
%union{
int intVal;
float floatVal;
}
%start program
%token <intVal> INTEGER_LITERAL
%token <floatVal> FLOAT_LITERAL
%token SEMI
%type <floatVal> exp
%type <floatVal> statement
%left PLUS MINUS
%left MULT DIV
The first part should look familiar: we're importing stuff that we want to use. After that it gets a little more tricky.
The union is a mapping of a "real" C++ type to what we're going to call it throughout this program. So, when we see intVal, you can replace that in your head with int, and when we see floatVal, you can replace that in your head with float. You'll see why later.
Next we get to the symbols. You can divide these in your head as terminals and non-terminals, like with the grammars we talked about before. Capital letters means terminals, so they don't continue to expand. Lowercase means non-terminals, so they continue to expand. That's just convention.
Each declaration (starting with %) declares some symbol. First, we see that we start with a non-terminal program. Then, we define some tokens. The <> brackets define the return type: so the INTEGER_LITERAL terminal returns an intVal. The SEMI terminal returns nothing. A similar thing can be done with non-terminals using type, as can be seen when defining exp as a non-terminal that returns a floatVal.
Finally we get into precedence. We know PEMDAS, or whatever other acronym you may have learned, which tells you some simple precedence rules: multiplication comes before addition, etc. Now, we declare that here in a weird way. First, lower in the list means higher precedence. Second, you may wonder what the left means. That's associativity: pretty much, if we have a op b op c, do a and b go together, or maybe b and c? Most of our operators do the former, where a and b go together first: that's called left associativity. Some operators, like exponentiation, do the opposite: a^b^c expects that you raise b^c then a^(b^c). However, we won't deal with that. Look at the Bison page if you want more detail.
Okay I probably bored you enough with declarations, here's the grammar rules:
// parser.y
%%
program: /* empty */
| program statement { cout << "Result: " << $2 << endl; }
;
statement: exp SEMI
exp:
INTEGER_LITERAL { $$ = $1; }
| FLOAT_LITERAL { $$ = $1; }
| exp PLUS exp { $$ = $1 + $3; }
| exp MINUS exp { $$ = $1 - $3; }
| exp MULT exp { $$ = $1 * $3; }
| exp DIV exp { $$ = $1 / $3; }
;
This is the grammar we were talking about before. If you're not familiar with grammars, it's pretty simple: the left hand side can turn into any of the things on the right hand side, separated with | (logical or). If it can go down multiple paths, that's a no-no, we call that an ambiguous grammar. This isn't ambiguous because of our precedence declarations - if we change it so that plus is no longer left associative but instead is declared as a token like SEMI, we see that we get a shift/reduce conflict. Want to know more? Look up how Bison works, hint, it uses an LR parsing algorithm.
Okay, so exp can become one of those cases: an INTEGER_LITERAL, a FLOAT_LITERAL, etc. Note it's also recursive, so exp can turn into two exp. This allows us to use complex expressions, like 1 + 2 / 3 * 5. Each exp, remember, returns a float type.
What is inside of the brackets is the same as we saw with the lexer: arbitrary C++ code, but with more weird syntactic sugar. In this case, we have special variables prepended with $. The variable $$ is basically what is returned. $1 is what is returned by the first argument, $2 what is returned by the second, etc. By "argument" I mean parts of the grammar rule: so the rule exp PLUS exp has argument 1 exp, argument 2 PLUS, and argument 3 exp. So, in our code execution, we add the first expression's result to the third.
Finally, once it gets back up to the program non-terminal, it will print the result of the statement. A program, in this case, is a bunch of statements, where statements are an expression followed by a semicolon.
Now let's write the code part. This is what will actually be run when we go through the parser:
// parser.y
%%
int main(int argc, char **argv) {
if (argc < 2) {
cout << "Provide a filename to parse!" << endl;
exit(1);
}
FILE *sourceFile = fopen(argv[1], "r");
if (!sourceFile) {
cout << "Could not open source file " << argv[1] << endl;
exit(1);
}
// Sets input for flex to the file instead of standard in
yyin = sourceFile;
// Now let's parse it!
yyparse();
}
// Called on error with message s
void yyerror(char *s) {
cerr << s << endl;
}
Okay, this is starting to get interesting. Our main function now reads from a file provided by the first argument instead of from standard in, and we added some error code. It's pretty self explanatory, and comments do a good job of explaining what's going on, so I'll leave it as an exercise to the reader to figure this out. All you need to know is now we're back to the lexer to provide the tokens to the parser! Here is our new lexer:
// scanner.lex
%{
extern "C" int yylex();
#include "parser.tab.c" // Defines the tokens
%}
%%
[0-9]+ { yylval.intVal = atoi(yytext); return INTEGER_LITERAL; }
[0-9]+.[0-9]+ { yylval.floatVal = atof(yytext); return FLOAT_LITERAL; }
"+" { return PLUS; }
"-" { return MINUS; }
"*" { return MULT; }
"/" { return DIV; }
";" { return SEMI; }
[ \t\r\n\f] ; /* ignore whitespace */
Hey, that's actually smaller now! What we see is that instead of printing, we're returning terminal symbols. Some of these, like ints and floats, we're first setting the value before moving on (yylval is the return value of the terminal symbol). Other than that, it's just giving the parser a stream of terminal tokens to use at its discretion.
Cool, lets run it then!
evan:ectlang/ $ bison parser.y
evan:ectlang/ $ flex scanner.lex
evan:ectlang/ $ g++ lex.yy.c -lfl
evan:ectlang/ $ ./a.out source.ect
Result: 6.2
Result: 2.63158
Result: 12
There we go - our parser prints the correct values! But this isn't really a compiler, it just runs C++ code that executes what we want. To make a compiler, we want to turn this into machine code. To do that, we need to add a little bit more...
Until Next Time...
I'm realizing now that this post will be a lot longer than I imagined, so I figured I'd end this one here. We basically have a working lexer and parser, so it's a good stopping point.
I've put the source code on my Github, if you're curious about seeing the final product. As more posts are released, that repo will see more activity.
Given our lexer and parser, we can now generate an intermediate representation of our code that can be finally converted into real machine code, and I'll show you exactly how to do it.
Additional Resources
If you happen to want more info on anything covered here, I've linked some stuff to get started. I went right over a lot, so this is my chance to show you how to dive into those topics.
- Flex codebase: https://github.com/westes/flex - the lexical analysis tool we used.
- Bison documentation: https://www.gnu.org/software/bison/ - the parser generator we used. Awesome documentation here.
- LALR parsing: https://web.cs.dal.ca/~sjackson/lalr1.html - a well made explanation on how LALR(1) parsers (like what Bison generates!) work.
- Resolving parsing conflicts: http://www.cs.ecu.edu/karl/5220/spr16/Notes/Bottom-up/conflict.html - how to fix shift/reduce or reduce/reduce conflicts, like the one we saw before.
- Chomsky hierarchy: https://en.wikipedia.org/wiki/Chomsky_hierarchy - didn't go much in detail about this, but we were using a context-free grammar so Bison can compile it. If you want context sensitivity, that's for later phases.
- Symbol table: https://www.tutorialspoint.com/compiler_design/compiler_design_symbol_table.htm - using symbol tables, how compilers deal with variables.
Oh, by the way, if you didn't like my phases of a compiler, here's an actual diagram. I still left off the symbol table and error handler. Also note that a lot of diagrams are different from this, but this best demonstrates what we're concerned with.






Top comments (10)
This is a very good introduction article. I've been working on and off on programming language design for 30 years or so, mostly as learning exercise. However in the past few years I've actually quit my job and done contract work so I can do it part-time, indeed writing a new full scope language (subtly named after myself even, ahhh hubris).
Here are my top three recommends:
My other recommendation, if you get more serious, is to find academic papers relating to compilers and technology to see what's out there. Many are summaries and/or improvements/extensions of other works, but it does eventually lead you to the gold nugget papers. After a week of searching I found one academic paper (with a sequel) which basically allowed me to leap in understanding several years ahead - why waste time working something out when somebody way smarter has done it for you.
It's also true that learning about how compilers and interpreters work really elevates your understanding of software engineering and programming. There's a reason why most undergraduate degrees have a "Compilers" course.
My "record" for implementing a language from scratch was one day, with less than 100 lines. I used it to write an interactive and offline test suite when I rewrote Unix kernel network APIs. It was a Lisp interpreter, which in general has very limited lexical, syntactical and semantic definitions, but is a powerful: see Clojure and Emacs for examples of this taken further.
Awesome, I really appreciate the reply! I'm still learning and love having the opportunity to move forward, so I really appreciate the references. Being part 1 I was very much planning on generating LLVM. Secretly the reason I wrote this was so I could dive a lot further into LLVM, as I already have done the flex/bison stuff a few times before, but this part got pretty in depth so I cut the post a little short.
I'm curious how working with compilers and language design works in the job market, though. I see companies like Google and Mozilla making programming languages, but most of that seems like R&D and hard to get into. Do you know how marketable an interest in compilers?
I look forward to part 2!
As for the job market, I'm not sure that there's a huge specific market for R&D jobs in building compilers. I could be wrong. My actual expertise is fairly varied, but in the past 15 years has been in games development. Know how to build interpreters and compilers is usually indirectly useful; you get to ramp up a little quick when using new languages or compilers. Usually there are occasional opportunities in many companies to apply the techniques or even build languages (eg. integrate Lua or Lisp into a game). Such knowledge rounds out a decent resume.
Thanks for sharing
This is kinda out of nowhere since it's been a while, but are there any plans to write the next article? I totally understand getting busy and/or losing track of ideas like this (I'm working on an occasionally-updated introduction to computer science in JavaScript series that hasn't been published to in over a month) but I would love to see the next steps.
Yes! I've been periodically working and making decent progress. Reason I made the post was to learn more about LLVM/backend work, so I'd rather know I have a solid understanding before trying to teach it, which has taken a bit longer than I'd thought. I'll have more time soon, but definitely not forgotten
Nice! I'll follow you so I'll get a notification when you're able to put it together. I definitely know about things taking longer than I thought they would.
I found this article because I'm in the process of building a quick-and-dirty interpreter for my own language (in JavaScript because it's easy and it's the language I know best) just for fun, and a lot of what you wrote here has been helpful.
I'll probably write a fuller implementation in another language once I have a working prototype for myself, and C++ is a possibility. I don't know C++ very well though, so it would be quite a challenge.
I was looking for the whole series actually. I hope you get to the end of the series. Thanks for the time and effort
Nice. Waiting for part 2 :)
Part 2: dev.to/evantypanski/writing-a-simp...