
This article contrasts the operational complexity of WebSockets and Long Polling using real world examples to promote Long Polling as a simpler alternative to Websockets in systems where a half-duplex message channel will suffice.
WebSockets
A WebSocket is a long lived persistent TCP connection (often utilizing TLS) between a client and a server which provides a real-time full-duplex communication channel. These are often seen in chat applications and real-time dashboards.
Long Polling
Long Polling is a near-real-time data access pattern that predates WebSockets. A client initiates a TCP connection (usually an HTTP request) with a maximum duration (ie. 20 seconds). If the server has data to return, it returns the data immediately, usually in batch up to a specified limit. If not, the server pauses the request thread until data becomes available at which point it returns the data to the client.
Analysis
WebSockets are Full-Duplex meaning both the client and the server can send and receive messages across the channel. Long Polling is Half-Duplex meaning that a new request-response cycle is required each time the client wants to communicate something to the server.
Long Polling usually produces slightly higher average latency and significantly higher latency variability than WebSockets.
WebSockets do support compression, but usually per-message. Long Polling typically operates in batch which can significantly improve message compression efficiency.
Scaling Up
We’ll now contrast the systemic behavior of server-side scalability for applications using primarily WebSockets vs Long Polling.
WebSockets
Suppose we have 4 app servers in a scaling group with 10,000 connected clients.
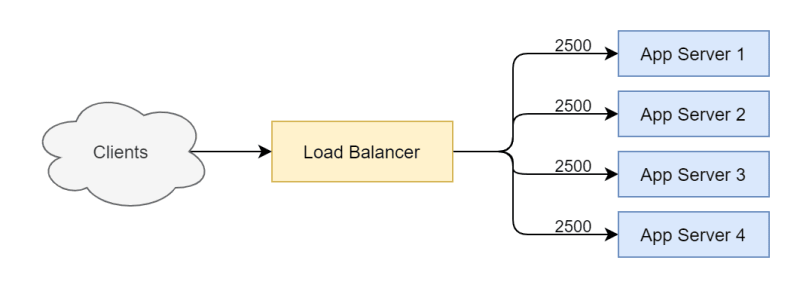
Now suppose we scale up the group by adding a new app server and wait for 60 seconds.

We find that all of the existing clients are still connected to the original 4 app servers. The Load Balancer may be intelligent enough to route new connections to the new app server in order to balance the number of concurrent connections so that this effect will diminish over time. However, the amount of time required for this system to return to equilibrium is unknown and theoretically infinite.
These effects could be mitigated by the application using a system to intelligently preempt web socket connections in response to changes in the scaling group's capacity but this would require the application to have special real-time knowledge about the state of its external environment which crosses a boundary that is typically best left uncrossed without ample justification.
Long Polling
Suppose we have the same 4 app servers in a scaling group with 10,000 connected clients using Long Polling.
Now suppose we scale up the group by adding a new app server and wait for 60 seconds.
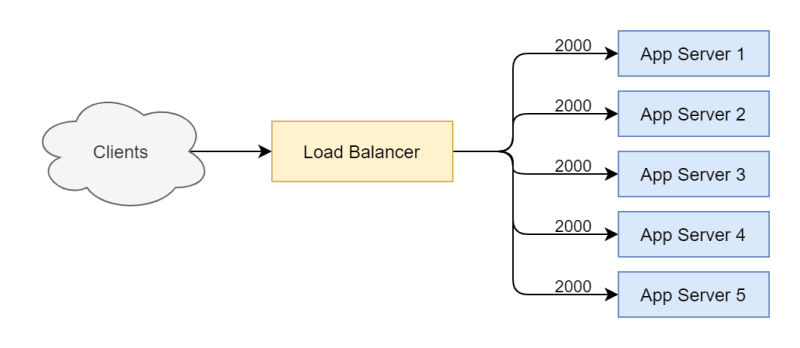
We observe that the number of open connections has automatically rebalanced with no intervention. We can even state declaratively that if the long poll duration is set to 60 seconds, then any autoscaling group will automatically regain equilibrium within 60 seconds of any membership change. This trait can be reflected in the application’s Service Level Objectives. These numbers are important because they are used by operators to correctly tune the app’s autoscaling mechanisms.
Analysis
Service Level Objectives are an important aspect of system management since they ultimately serve as the contractual interface between dev and ops. If an application’s ability to return to equilibrium after scaling is unbounded, a change in application behavior is likely warranted.
Scaling Down
The following example illustrates difficulties encountered by a real world device management software company operating thousands of 24/7 concurrent WebSocket connections from thousands of data collection agents placed inside corporate networks.
The System

A Data Collection Agent, written in Go, is distributed as an executable binary that runs as a service on an agent machine scanning local networks for SNMP devices and reporting SNMP data periodically to the application in the cloud.
One key feature of the product was the ability for a customer to interact with any of their devices in real time from anywhere in the world using a single page web application hosted in the cloud. Because each agent resides on a customer network behind a firewall, the agents would need to initiate and maintain a WebSocket connection to the application in the cloud as a secure full-duplex tunnel. The web service sends commands to agents and agents send data to the web service all through a single persistent TCP connection.
The Problem
There was one big unexpected technical challenge faced by the team when deploying this system that made deployments risky. Whenever a new version of the app server was deployed to production, the system would be shocked by high impulse reconnect storms originating from the data collection agents.
If a server has 2500 active connections and you take it out of service, those 2500 connections will be closed simultaneously and all the agents will reopen new connections simultaneously. This can overwhelm some systems, especially if the socket initialization code touches the database for anything important (ie. authorization). If an agent can’t establish a connection before the read deadline, it will retry the connection again which will drown the app servers even further, causing an unrecoverable negative feedback loop.
This proclivity toward failure caused management to change their policies regarding deployments to reduce the number of deployments as much as possible to avoid disruption.
The Solution
The problem was partially solved by implementing strict exponential retry policies on their clients. This solution was effective enough at reducing the severity of retry storms on app deployment to be considered a good temporary solution. However, deployments were still infrequent by design and the high impulse load spikes weren’t gone, they just no longer produced undesirable secondary effects.
Analysis
This temporary solution is only possible in situations where the server has complete control over all of its clients. In many scenarios this may not be the case.
If the system were originally modeled to receive commands from the server by Long Poll and push data to the server through a normal API, the load would be evenly spread.
If using a Long Poll architecture, the deployment system would replace a node by notifying the load balancer that the node is going out of service to ensure the node doesn’t receive any new connections, then wait 60 seconds for existing connections to drain in accordance with the service’s shutdown grace period SLO, then take the node offline with confidence. The resulting load increase on other nodes in the group would be gradual and roughly linear.
When it comes to distributed systems and their scalability, people often focus on creating efficient systems. Efficiency is important but usually not as important as stability. High impulse events like reconnect storms can produce complex systemic effects. Left unattended, they often amplify the severity of similar effects in different parts of the system in ways that are both unexpected and difficult to predict.
If you fail to solve enough of these types of problems, you may soon find yourself in situations where so many components are failing so simultaneously that it’s exceptionally difficult to discern the underlying cause(s) empirically from logs and dashboards. An application’s architecture must be designed primarily in accordance with principle and remain open to modification in response to statistical performance analysis.
Conclusion
WebSockets are appropriate for many applications which require consistent low latency full duplex high frequency communication such as chat applications. However, any WebSocket architecture that can be reduced to a half-duplex problem can probably be remodeled to use Long Polling to improve the application’s runtime performance variability, reducing operational complexity and promoting total systemic stability.





Top comments (1)
Thanks for great in depth explanation.