
Table of contents
Introduction
Functional Programming is a declarative programming paradigm, in contrast to imperative programming paradigms.
Declarative programming is a paradigm describing WHAT the program does, without explicitly specifying its control flow.
Imperative programming is a paradigm describing HOW the program should do something by explicitly specifying each instruction (or statement) step by step, which mutate the program's state.
This "what vs how" is often used to compare both of these approaches because... Well, it is actually a good way to describe them.
Granted, at the end of the day, everything compiles to instructions for the CPU. So in a way, declarative programming is a layer of abstraction on top of imperative programming.
At some point, the state of the program must be changed in order for things to happen, and these changes can only occur with instructions moving data from one location (cache, memory, hard drive...) to another. But we are not here to talk about low-level programming, so let's focus on high-level languages instead.
The transformation from declarative to "imperative code" is generally made by engines, interpreters, or compilers.
For example, SQL is a declarative language. When using the SELECT * FROM users WHERE id <= 100 query, we are expressing (or declaring) what we want: the first 100 users ever registered in the database. The way how these rows are retrieved is completely delegated to the SQL engine: can it use an index to accelerate the query? Should/Can it use multiple CPU cores to finish earlier?
From a developer's point of view, we have no idea how these data are actually retrieved. And we don't really care, unless we are investigating some performance issues. All we care about is telling the program what data we want to retrieve, and not how to do it. The engine/compiler is smart enough to find the most optimal way to do that anyway.
For languages that use a declarative paradigm (e.g. Haskell, SQL), this "underlying imperative world" is abstracted/hidden to the developers. It is something we don't have to worry about.
For languages that are multi-paradigms (e.g. JavaScript, Scala), there is still the possibility to write imperative code. This allows us to write declarative code based on imperative code that we wrote ourselves. This can be useful to support FP features that are not built-into the language for example, or just to make the code more "declarative", which makes it more readable and understandable, in my opinion.
The imperative code is abstracted by the declarative one, which is the one used by the developers to actually write the software. The imperative part becomes an implementation detail of the software.
Making a chocolate cake
Let's take an example from the real world: we would like to make a chocolate cake. How would that look like with these 2 paradigms?
The imperative way
- First, turn on the oven to preheat it at 180°C.
- Next, add flour, sugar, cocoa powder, baking soda and salt to a large bowl, then stir the mixture with a paddle.
- Then, add milk, vegetable oil, eggs and vanilla extract to the mixture, and mix together on medium speed until well combined.
- Distribute the cake batter evenly in a large cake pan, then bake it for approx. 30 minutes.
- Remove the pan from the oven with a pot holder, let it cool for 10 minutes.
- Finally, remove the cake from the pan with the tapping method, and frost it evenly with chocolate frosting.
The declarative way
- You have to preheat the oven to 180 °C.
- You have to mix dry ingredients in a bowl.
- Once dry ingredients are mixed, you have to add wet ingredients to the mixture, and mix together to form the cake batter.
- Once the oven and batter are ready, you have to put the batter in a pan, then bake it for 30 minutes.
- Once baked, you have to remove the pan from the oven and let it cool for 10 minutes.
- Finally, you have to remove the cake from the pan, and frost it.
- Ready? Go!
Analysis
In the imperative way, we are told what to do, and more importantly how to do it: use a large bowl, mix with a paddle, mix at medium speed, use a large pan, distribute batter evenly, remove pan with a pot holder, use the tapping method, frost evenly.
These details are great when actually making a cake, especially as a beginner. But when describing how to make one, on a "higher level" of abstraction, we don't need all these information.
Furthermore, we are actually doing something at each step, i.e. we are changing the world around us, step by step. If we choose to stop at an intermediate step, then we basically "wasted" all the tools and ingredients from the previous steps.
In the declarative way, we are told what we will have to do to make the cake. Nothing actually happens until the last step, i.e. the world doesn't change until we have reached the 7th step.
In other words, we are preparing all the steps in advance, then at the very end, we are doing what was described. How do we perform the actions described in these steps though? It's abstracted: all the "how" parts are provided as later as possible, between the "Ready?" and "Go!", either by the developer (for multi-paradigms languages) or by the engine/compiler. For example, this is where the binding between "remove the pan from the oven" and "using a pot holder" is done. We could also bind it to "using the pan handle", without changing the definition of the 5th step.
Some examples
Let's say we want to double every value of a given list of numbers. There are plenty of ways to iterate over a list and transform each of its elements in JavaScript:
- Declarative: recursive function, or functions already available such as the
mapandreducemethods of arrays - Imperative:
forloop,whileloop
To demonstrate that imperative code can be abstracted by declarative code, we could use a for loop and hide it inside a transformEachElement function:
// "hidden" in a utils/helper/whatever module, or library-like
function transformEachElement<A, B>(
elements: A,
action: (element: A) => B
): B[] {
const result = []
for (let i = 0; i < elements.length: i++) {
result.push(action(elements[i]))
}
return result
}
// What do we want? Double each number of a given list
const res = transformEachElement([1, 2, 3], n => n * 2)
But we could use map directly as it's already declarative, and widely known for this type of use case:
const res = [1, 2, 3].map(n => n * 2)
Here is another example, where we want to target the text from an element of a web page. This element's location is a few levels down in the elements hierarchy (called the DOM tree). The twist is that each of these elements may not exist in practice.
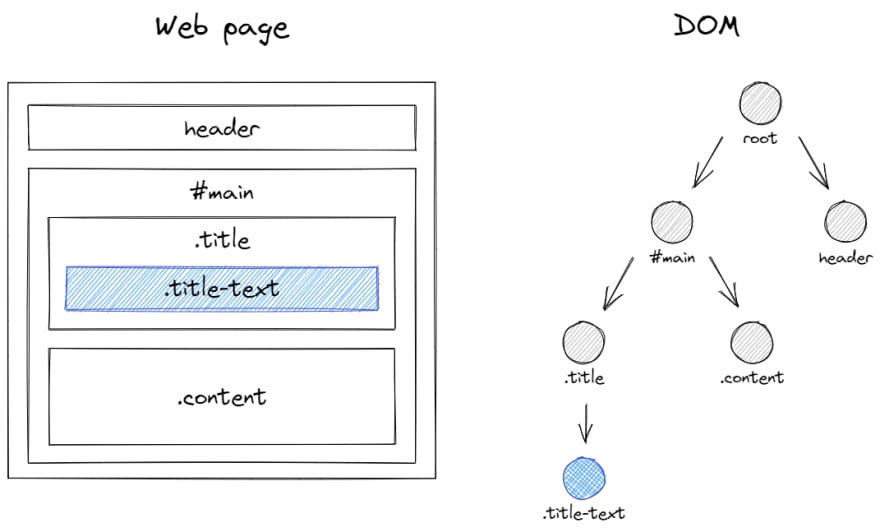
So, each time we progress by one node in the tree, we have to check if the next node is available or not.
The imperative way could look like this:
function getMainTitle(): string | null {
const main = document.getElementById('main')
if (main !== null) {
const title = main.querySelector('.title')
if (title !== null) {
const text = title.querySelector<HTMLElement>('.title-text')
if (text !== null) {
return text.innerText
} else {
return null
}
} else {
return null
}
} else {
return null
}
}
This is pretty verbose, and the more depth there is to reach an element, the bigger the pyramid of doom gets.
Additionally, we have leaked an implementation detail: a node that doesn't exist has the value null. It could have been undefined, or 'nothing', or something else entirely. The point is that we have to understand that null is the magic value expressing the absence of an element in the tree here. It should not be necessary to know that to understand what this function does.
Here is a more declarative approach:
const main: Option<Element> =
Option(document.getElementById('main'))
function getTitle(main: Element): Option<Element> {
return Option(main.querySelector('.title'))
}
function getTitleText(title: "Element): Option<HTMLElement> {"
return Option(
title.querySelector<HTMLElement>('.title-text')
)
}
function getMainTitle(): Option<string> {
return main
.flatMap(getTitle)
.flatMap(getTitleText)
.map(text => text.innerText)
}
In this second version, all we care about is accessing an element in the tree, where each intermediate element could be missing. In other words, we have written "what" to do in order to access the element containing the text we are looking for.
This supposes that we have access to some Option data structure in our code base. There are plenty of articles available on the Internet that talk about this Option (also known as Maybe) data type. Essentially, it allows us to express the possible absence of a value, transform it if the value is available, and combine it with other possible missing values, all that in a declarative way.
In fact, this data type is so useful that some languages already provide it in their standard library (e.g. Scala, Haskell, F#), even the more mature ones (e.g. Optional in Java, C++).
The
flatMapandmapterms may seem "mystical" at this point. We will talk about them by the end of this series, in the article about algebraic data structures and type classes. In functional programs, you will often encounter these functions or their equivalent, depending on the language:
mapis also known asfmap,lift,<$>flatMapis also known asbind,chain,>>=
A couple of years ago (Dec. 2019), the optional operator proposal reached stage 4 in the EcmaScript specification, used for both JavaScript and TypeScript. This allows us to greatly simplify the code from above, without relying on any library:
function getMainTitle(): string | null {
return document.getElementById('main')
?.querySelector('.title')
?.querySelector<HTMLElement>('.title-text')
?.innerText
}
This still "leaks" the fact that either null or undefined values should be used to mark an element as missing, but it is still way more expressive than the first imperative version from earlier.
When to use declarative code
This section applies only to muli-paradigms languages. Obviously, if you are using a functional language such as Haskell, you are always using declarative code.
So, it is possible to make imperative code look like declarative code, to some extent. In such case, I would suggest isolating the imperative parts from the rest of the code base, to make sure developers use the "declarative" functions instead.
In multi-paradigms languages, the scale between declarative and imperative is not a clear black/white separation, but rather multiple shades of grey. It is up to us to determine which shade is the best for our projects and teams.
Here is a non-exhaustive list of pros and cons for each of these approaches, based on my experience:
Declarative
| Pros | Cons |
|---|---|
| Better readability and understanding of the code | More lines of code, where a potential bug could hide |
| Better control over the actual execution of the changes to the world | Potential loss of performance, due to more memory allocation and intermediate function calls |
| Longer debugging, due to bigger stack traces | |
| Developers are usually less comfortable with this way of programming |
Imperative
| Pros | Cons |
|---|---|
| Less code overall, as there is no need to wrap imperative code inside declarative functions | More time taken to read and understand what the code does |
| Shorter debugging, due to smaller stack traces | But harder debugging overall, due to state mutations and "less-controlled" changes to the world |
| Developers are usually more comfortable with this way of programming |
Since code is destined to be read and understood by human beings, I think it is a good practice to use more declarative programming in our softwares.
Sometimes, performance is critical and requires the use of imperative programming (we are talking about multi-paradigms languages here). In such cases, comments and documentation are crucial to understand the code base. Otherwise, some exceptions put aside, code should be self-explanatory through good naming and declarative steps, and should not require comments to understand it well.
For strictly-declarative languages such as Haskell and SQL, the compiler/engine makes the best optimizations possible; so there is no need (and no way anyway) to write imperative code to improve performance.
Conclusion
In this article, I tried to illustrate (with some examples) the difference between these 2 approaches, and the advantages of the declarative way. The biggest benefit is making the code more readable and understandable.
Misunderstanding the responsibility of some part of the code base is one of the most common reasons why bugs are introduced in the first place. It is also one of the reasons why adding improvements and features takes more time, as we need to first understand what the code does before making any changes.
Functional Programming is about expressing "what" we want to do with data, but not actually doing anything until the very last moment. Doing something requires changing state and running statements. These parts are handled by engines/interpreters/compilers, since they know "how" to efficiently do "what" we wrote in the code base.
It is not a requirement to fully understand this way of writing code, because it will come naturally the more functional code you write. By going through the articles of this series, you will see that declarative programming is ubiquitous, despite not being mentioned explicitly.
Thank you for reading this far! As always, feel free to leave a comment if need be. The next article will talk about pure functions and referential transparency. See you there!
Special thanks to Tristan Sallé for reviewing the draft of this article.
Photo by Xavi Cabrera on Unsplash.
Pictures made with Excalidraw.





Top comments (6)
Actually, SQL is indeed imperative, not declarative.
When you say "SELECT this and that such that bla bla bla", you're giving instructions. You're instructing to "select" (according to certain condition), and to "select" is an action.
A true declarative statement would be one expressed, for example, in first order logic. Taking on your example, where you select all the users such that their ids are < 100, in first order logic it would be:
{x / x ∈ users and x.id < 100}
That's a true declarative statement. You're saying: this is the set of persons whose ids are below to 100. You're telling the WHAT, not the HOW.
Indeed, and the second cake recipe is also still imperative. This would be the declarative version:
* Keeping "30 minutes" verges on becoming imperative. A more declarative approach to this particular part would be to specify a final moisture content, weight, or other means of determining doneness.
Perhaps it would be more declarative yet to format those steps with a more functional syntax, omitting the intermediate labels like "Batter", and using parentheses as necessary to delimit order-relevant groups. Or perhaps that would just more "functional", and equally as declarative.
I think we must admit that that there is a gradient, rather than a binary distinction, between declarative and imperative programming. The most extreme end of declarativism would be to describe the chemical structures and physical composition of the final cake, and leave it at that. But that furthest end of the declarativism gradient is achievable only in small scenarios.
{x / x ∈ users and x.id < 100}is useless if users are never created (they certainly didn't exist before the big bang, and aren't timeless constructs like gravity) - in the grand scheme of things, derivation is going to need to be involved, so the program as a whole cannot be as declarative as that one snippet (the formation of users must occur before the formation of the query result). Some amount of ordering and verb choice will either be important to the author of an application, or required by the engine. Ultimately, declarative programming is not about removing all traces of ordering & verb choice from programming, but rather, it's about removing the need for incidental and inevitable ordering & verb choice from programming. What can be considered incidental or inevitable depends on the engine that evaluates the program - some chefs may implicitly know that the cake's temperature should be below the frosting's fat's melting point before it is frosted, while others need a hint.Nice explanation. Thank you!
Great article, thanks!
A small nerd remark: the examples with DOM are good for illustration purposes, but not very correct in a practical way - you can just use the magic of css selectors and it will be enough
Great breakdown and examples of the distinctions!
How about my version of the same:
Declarative vs imperative