
I've been somewhat obsessed with creating workflow engines for the better part of a decade. The idea of constructing a 'mega' machine from an army of smaller machines never seems to get old for me.
At their core, workflow engines are responsible for executing a series of tasks (typically referred to as a 'job', 'pipeline' or 'workflow') over a cluster of machines (typically referred to as 'workers' or nodes) as quickly and as efficiently as possible.
Building a workflow engine comes with a bunch of interesting challenges. Here's a short and highly non-exhaustive list:
What do you use to author workflows? Do you use a general-purpose programming language? a configuration-type language like JSON or YAML or do you roll your own DSL (Domain Specific Language)?
How do we decide which tasks go to which workers such that busy workers are not overloaded while others are idle?
How do we deal with the requirement to scale up or down the capacity in response to fluctuations in computational demand?
How do we deal with intermittent task failures?
How do we deal with worker crashes?
How do we deal with a situation where we have more tasks to execute than available capacity?
Let's put some rubber on the road
The first time I needed to actually build a workflow engine was while working for a video streaming startup. At the time, the company was outsourcing all its video processing needs to another company.
The existing process was slow, expensive and brittle. The company was regularly getting new content (movies, trailers, bonus video material, closed captions etc.) and we needed a way to quickly process this content in order to get it up on the service for customers to enjoy.
Moreover, the existing process was quite rigid and any changes to it (e.g. to introduce a new audio technology) took months or were simply not possible. I suggested to build a proof-of-concept that would allows us to bring the work in-house and luckily my managers were open to the idea.
At this point, you're probably asking yourself why would you want to be build one when there are a million open-source and commercial options out there?
True, there are many options out there. And we looked at a good number before we made the decision to build one ourselves. But at least at the time (circa 2014), many of the existing options were either not designed for a distributed environment, were designed more particularly for data-processing use cases, were seemingly abandoned, or simply felt over-engineered to our taste.
The initial iteration of the workflow engine allowed us to start processing 'low-risk' content such as trailers, and as we gained confidence in the new system we slowly phased out the old process completely.
Later on, when a co-worker left to another media company that needed a similar system, he asked me if I'd like to come over and do it all over again from scratch. Naturally, I agreed. Our 2.0 was similar in spirit but a lot of the lessons learned from the old design were fixed in the new design.
Meet Tork
After building two proprietary workflow engines for highly specialized use cases I had an itch to see if other companies - possibly with vastly different use cases - could also benefit from a similar system. So I decided to build an open-source version of it.
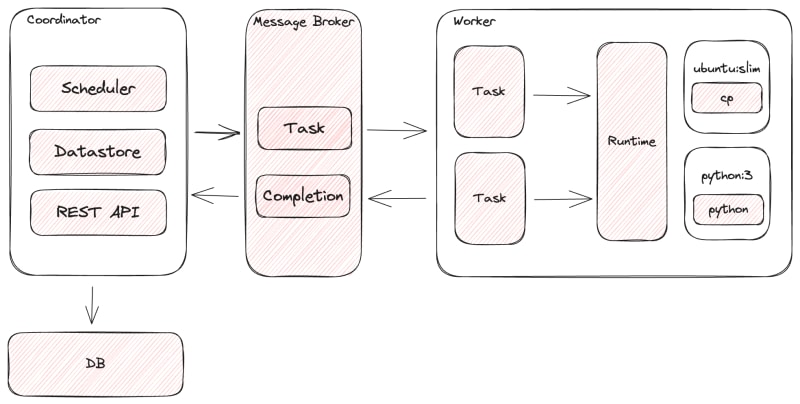
Tork is a Golang-based implementation which is very similar in spirit to its closed-source predecessors. It can run in a 'standalone' mode on a laptop or deployed to a huge cluster of machines depending on your need.
The main components of Tork are:
Coordinator: responsible for managing the lifecycle of jobs and tasks, routing tasks to the right workers and for dealing with task execution errors.
Worker: responsible for executing tasks according to the instructions of the Coordinator. Workers are stateless so it's easy to add and remove them as demand for capacity changes.
Broker: the means of communication between the Coordinator and worker nodes.
Datastore: holds the state for tasks and jobs.
Runtime: tasks are executed by means of a runtime which translates the task into actual executable. Currently only Docker is supported due to its ubiquity and large library of images, but there are plans to add support for Podman and WASM in the future.
If you're interested in checking it out, you can find the project on Github:
- Backend: https://github.com/runabol/tork
- Web UI: https://github.com/runabol/tork-web





Top comments (1)
This is interesting